
BeeMachine was developed by Brian Spiesman in collaboration with:
Claudio Gratton, University of Wisconsin – Madison
William Hsu, Kansas State University
Brian McCornack, Kansas State University
Support
BeeMachine was funded by USDA NIFA and Kansas State University. Computer vision models were developed with data primarily from the Global BIodiversity Infrastructure Facility (GBIF). We are also grateful for data provided by others, including the Wisconsin Bumble Bee Brigade, the
Hanamaru Maruhana Project
, and Jerry Cole. I am grateful for the volunteer participants in these programs that share their images and taxonomic expertise.
Our Computer Vision Model
BeeMachine is able to identify bee species from around the world. But if it isn't sure about the species it will give a genus-level prediction. Because flowers are often visited by other kinds of insects that can sometimes be confused with bees, we now include the ability to differentiate bees from wasps, flies, beetles, and butterflies/moths. Overall test accuracy on the current algorithm is 93.7% (99.4% top-3) but this varies by species depending on the number of training images and their level of morphological variability (see figures below). BeeMachine uses a convolutional neural network, modified from EfficientNetV2, and was trained on over 1.2 million images.
The 132 bumble bee taxa recognized by BeeMachine
Other groups that BeeMachine can recognize include 89 other bee species, 128 bee genera, and has general categories for wasps, flies, hoverflies, beetles, and butterflies/moths.
| Acamptopoeum sp. |
| Agapostemon sp. |
| Agapostemon splendens |
| Agapostemon virescens |
| Alloscirtetica sp. |
| Amegilla sp. |
| Amphylaeus sp. |
| Ancylandrena sp. |
| Andrena sp. |
| Andrena barbilabris |
| Andrena bicolor |
| Andrena cineraria |
| Andrena clarkella |
| Andrena denticulata |
| Andrena dorsata |
| Andrena dunningi |
| Andrena erigeniae |
| Andrena flavipes |
| Andrena florea |
| Andrena fulva |
| Andrena haemorrhoa |
| Andrena hattorfiana |
| Andrena hirticincta |
| Andrena milwaukeensis |
| Andrena nigroaenea |
| Andrena nitida |
| Andrena nubecula |
| Andrena prunorum |
| Andrena vaga |
| Andrena ventralis |
| Andrena wilkella |
| Anthidiellum sp. |
| Anthidium sp. |
| Anthidium florentinum |
| Anthidium maculosum |
| Anthidium manicatum |
| Anthidium oblongatum |
| Anthidium punctatum |
| Anthidium septemspinosum |
| Anthophora sp. |
| Anthophora abrupta |
| Anthophora bimaculata |
| Anthophora bomboides |
| Anthophora californica |
| Anthophora furcata |
| Anthophora pacifica |
| Anthophora plumipes |
| Anthophora quadrimaculata |
| Anthophora retusa |
| Anthophora terminalis |
| Anthophora urbana |
| Anthophora villosula |
| Anthophorula sp. |
| Apis sp. |
| Apis cerana |
| Apis dorsata |
| Apis florea |
| Apis laboriosa |
| Apis mellifera |
| Ashmeadiella sp. |
| Augochlora sp. |
| Augochlorella sp. |
| Augochloropsis sp. |
| Brachymelecta sp. |
| Braunsapis sp. |
| Cadeguala sp. |
| Calliopsis sp. |
| Callomelitta sp. |
| Camptopoeum sp. |
| Caupolicana sp. |
| Centris sp. |
| Ceratina sp. |
| Ceylalictus sp. |
| Chalepogenus sp. |
| Chelostoma sp. |
| Coelioxys sp. |
| Coleoptera sp. |
| Colletes sp. |
| Colletes cunicularius |
| Colletes hederae |
| Colletes inaequalis |
| Corynura sp. |
| Dasypoda sp. |
| Dasypoda hirtipes |
| Diadasia sp. |
| Dianthidium sp. |
| Dieunomia sp. |
| Dioxys sp. |
| Diphaglossa gayi |
| Diptera sp. |
| Dufourea sp. |
| Epeoloides sp. |
| Epeolus sp. |
| Epicharis sp. |
| Ericrocis sp. |
| Euaspis sp. |
| Eucera sp. |
| Eufriesea sp. |
| Euglossa sp. |
| Euhesma sp. |
| Eulaema sp. |
| Euryglossa sp. |
| Exaerete sp. |
| Exomalopsis sp. |
| Exoneura sp. |
| Exoneuridia sp. |
| Florilegus sp. |
| Gaesischia sp. |
| Habropoda sp. |
| Halictus sp. |
| Halictus ligatus |
| Halictus rubicundus |
| Halictus scabiosae |
| Halictus tripartitus |
| Heriades sp. |
| Hesperapis sp. |
| Holcopasites sp. |
| Hoplitis sp. |
| Hylaeus sp. |
| Hylaeus leptocephalus |
| Hylaeus modestus |
| Hyleoides sp. |
| Icteranthidium sp. |
| Lasioglossum sp. |
| Leioproctus sp. |
| Lepidoptera sp. |
| Lipotriches sp. |
| Lithurgopsis sp. |
| Lithurgus sp. |
| Macropis sp. |
| Macrotera sp. |
| Manuelia sp. |
| Megachile sp. |
| Megachile ericetorum |
| Megachile latimanus |
| Megachile perihirta |
| Megachile pugnata |
| Megachile sculpturalis |
| Megachile xylocopoides |
| Megandrena sp. |
| Melecta sp. |
| Meliponini sp. |
| Melissodes sp. |
| Melissodes bimaculatus |
| Melissodes desponsus |
| Melissoptila sp. |
| Melitoma sp. |
| Melitta sp. |
| Melitturga sp. |
| Mellitidia sp. |
| Meroglossa sp. |
| Mesocheira bicolor |
| Micralictoides sp. |
| Nomada sp. |
| Nomada goodeniana |
| Nomada lathburiana |
| Nomia sp. |
| Nomioides sp. |
| Notanthidium sp. |
| Osmia sp. |
| Osmia bicolor |
| Osmia bicornis |
| Osmia caerulescens |
| Osmia cornuta |
| Osmia lignaria |
| Othinosmia sp. |
| Oxaea sp. |
| Pachyprosopis sp. |
| Palaeorhiza sp. |
| Panurginus sp. |
| Panurgus sp. |
| Paragapostemon coelestinus |
| Paranthidium sp. |
| Paratetrapedia sp. |
| Pasites sp. |
| Patellapis sp. |
| Peponapis sp. |
| Perdita sp. |
| Protandrena sp. |
| Protosmia sp. |
| Protoxaea sp. |
| Pseudapis sp. |
| Pseudaugochlora sp. |
| Pseudoanthidium sp. |
| Pseudopanurgus sp. |
| Ptiloglossa sp. |
| Ptilothrix sp. |
| Rhodanthidium sp. |
| Rophites sp. |
| Ruizantheda sp. |
| Scrapter sp. |
| Sphecodes sp. |
| Stelis sp. |
| Svastra sp. |
| Syntrichalonia sp. |
| Syrphidae sp. |
| Systropha sp. |
| Tetralonia sp. |
| Tetraloniella sp. |
| Thalestria sp. |
| Thygater sp. |
| Thyreus sp. |
| Trachusa sp. |
| Trichocolletes sp. |
| Triepeolus sp. |
| Wasp |
| Xenoglossa sp. |
| Xylocopa sp. |
| Xylocopa aestuans |
| Xylocopa augusti |
| Xylocopa caffra |
| Xylocopa californica |
| Xylocopa flavorufa |
| Xylocopa latipes |
| Xylocopa micans |
| Xylocopa pubescens |
| Xylocopa sonorina |
| Xylocopa tabaniformis |
| Xylocopa tenuiscapa |
| Xylocopa violacea |
| Xylocopa virginica |
| Zacosmia maculata |
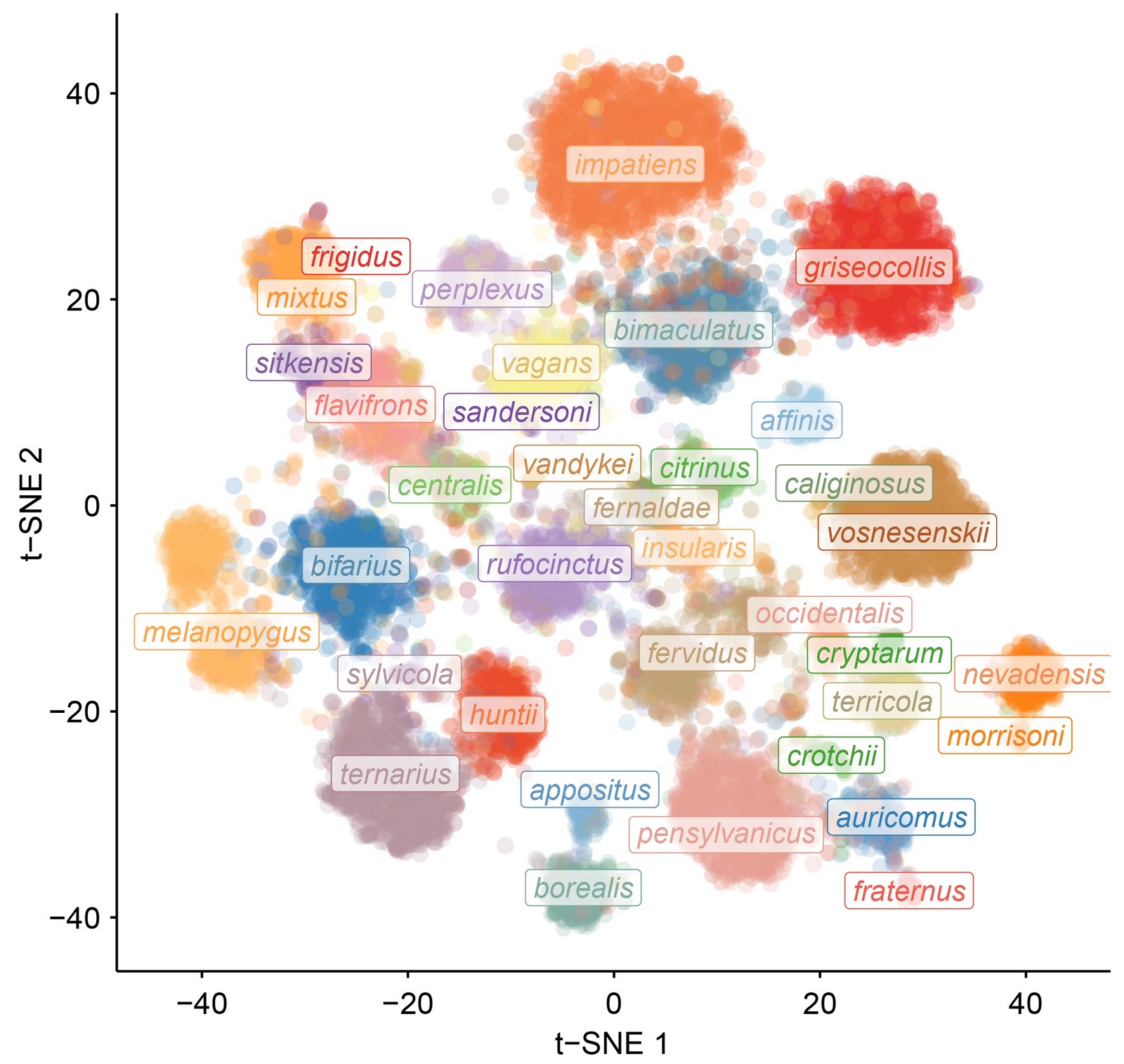
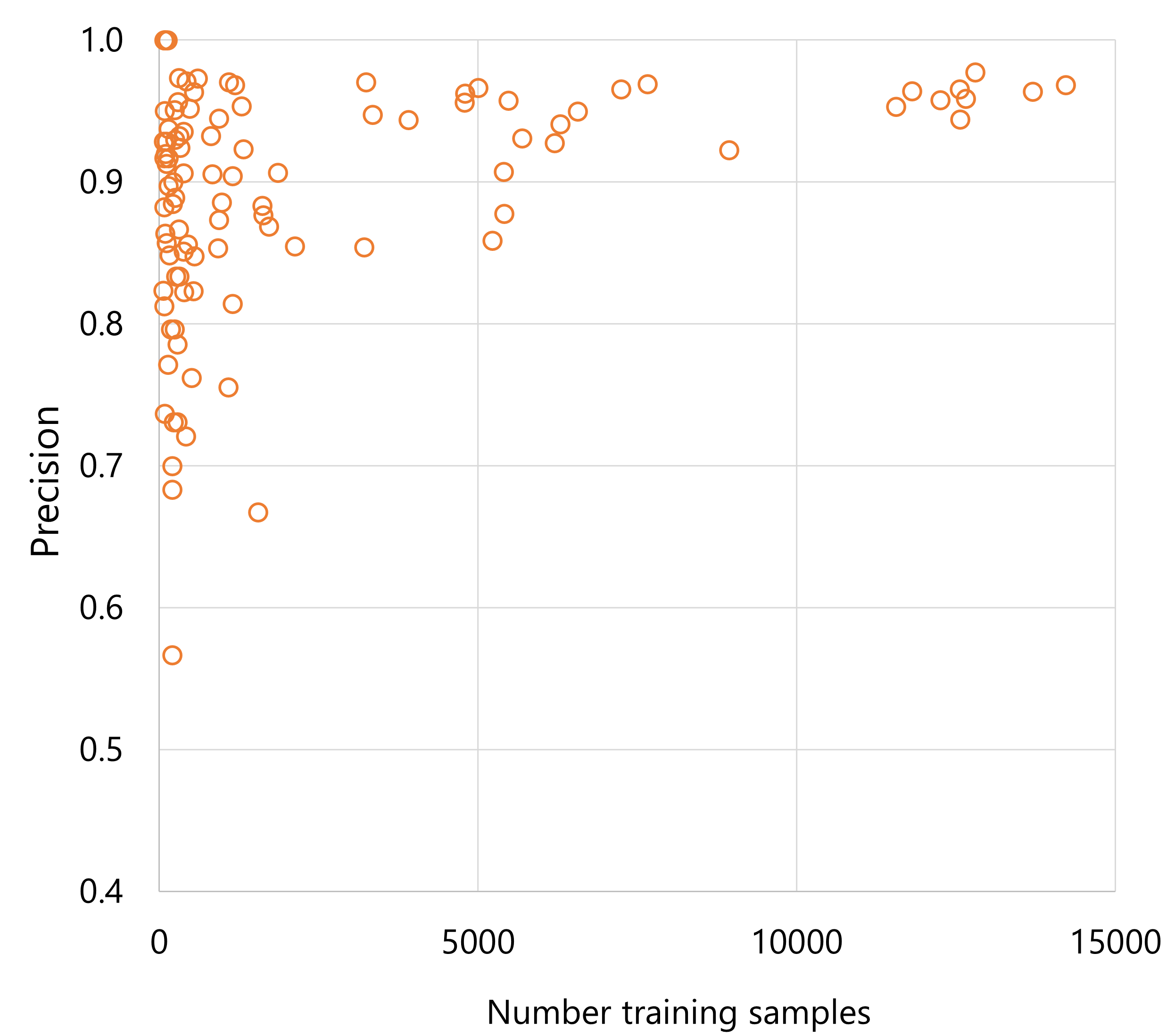
Precision is generally greater for species that were trained on more images. We can use this information to target particular species for acquiring more images to improve the classification model.